Current Projects
This is a selection of the main projects of the Measurement and Machine Learning Lab. All team members are involved in other projects besides the ones listed below:
Detection and Classification of Misspecifications in Structural Equation Modeling using Machine Learning (funded by the German Research Foundation, DFG GO 3499/1-1)
In this project, modern approaches from computational statistics such as machine learning and meta-heuristic optimization algorithms are used to develop novel methods for detecting and classifying misspecifications in structural equation models as well as automatically re-specifying measurement models in a fully data-driven manner. By integrating various nuisance parameters (e.g., sample and model size) as features in the prediction model, the new approach promises to consider their interactions with model fit indices. Accordingly, the ML-based model fit evaluation addresses shortcomings in the current practice that often relies on simple rules of thumb combining fixed cutoffs and model fit indices.

Figure 1: Abstract visualization of a tree-based ML approach taking different nuisance parameters into account when identifying model misspecifications in SEM. Created with DALL-E.
Selected Publications and Preprints:
Goretzko, D., Siemund, K., & Sterner, P. (2024). Evaluating Model Fit of Measurement Models in Confirmatory Factor Analysis. Educational and Psychological Measurement. https://doi.org/10.1177/00131644231163813
Partsch, M. V., Sterner, P., & Goretzko, D. (2025). A simulation study on the interaction effects of underfactoring and nuisance parameters on model fit indices. Structural Equation Modeling: A Multidisciplinary Journal. https://doi.org/10.1080/10705511.2025.2514592
Partsch, M. V., & Goretzko, D. (2025). Detecting model misfit in structural equation modeling with machine learning—A proof of concept. Multivariate Behavior Research. https://doi.org/10.1080/00273171.2025.2552304
Goretzko, D., & Partsch, M. V. (2025). Predicting measurement model misfit with machine learning while accounting for nuisance parameters — An illustration. Psychological Test Adaptation and Development. https://doi.org/10.1027/2698-1866/a000111
A New Perspective on Measurement Invariance
In this project, we develop new data-driven methods to a) investigate measurement invariance more holistically (i.e., with regard to many covariates and without constraining the analysis model too much), b) address measurement invariance at the early stages of scale development, c) inform a causal perspective on measurement, and d) ultimately make psychological measurements more robust and generalizable.
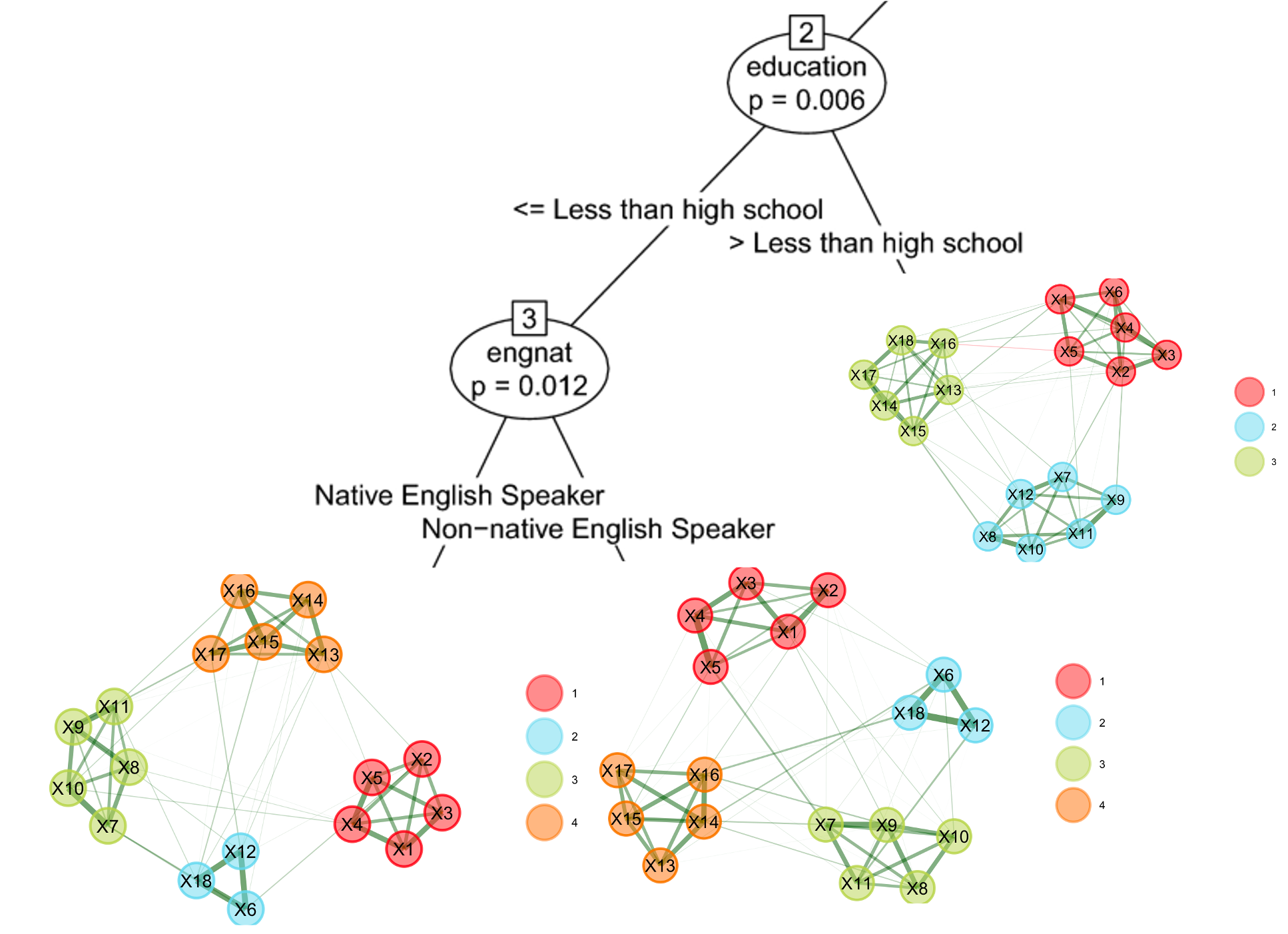
Figure 2: Visualization of the new EGA trees approach that can be used to identify differences in the latent dimensionality as the cause of configural non-invariance.
Selected Publications and Preprints:
Sterner, P., & Goretzko, D. (2024) Exploratory Factor Analysis Trees: Evaluating Measurement Invariance Between Multiple Covariates. Structural Equation Modeling: A Multidisciplinary Journal. https://doi.org/10.1080/10705511.2023.2188573
Sterner, P., Pargent, F., Deffner, D., & Goretzko, D. (2024) A Causal Framework for the Comparability of Latent Variables. Structural Equation Modeling: A Multidisciplinary Journal. https://doi.org/10.1080/10705511.2024.2339396
Sterner, P., de Roover, K., & Goretzko, D. (2025) New Developments in Measurement Invariance Testing-An Overview and Comparison of EFA-based Approaches. Structural Equation Modeling: A Multidisciplinary Journal. https://doi.org/10.1080/10705511.2024.2393647
Straub, N., Goretzko, D., & Sterner, P. (2025) Assessing Measurement Invariance with Exploratory Factor Analysis Trees: A Practical Guide. European Journal of Psychological Assessment. https://doi.org/10.1027/1015-5759/a000898
Goretzko, D., & Sterner, P. (2025). Exploratory Graph Analysis Trees-A Network-based Approach to Investigate Measurement Invariance with Numerous Covariates. Psychological Methods. https://doi.org/10.1037/met0000796
Schuhbeck, T. M. B., Sterner, P., & Goretzko, D. (2025). Quantifying Measurement Non-Invariance Beyond Simple Structure: The Closed Formulas of Universal Effect Size Measures for MI. Structural Equation Modeling: A Multidisciplinary Journal. https://doi.org/10.1080/10705511.2025.2570447
Sterner, P., Pargent, F., & Goretzko, D. (2026). Don’t let MI be misunderstood: Measurement invariance is more than a statistical assumption. Current Research in Ecological and Social Psychology. https://doi.org/10.1016/j.cresp.2025.100261
Dimensionality Assessment in Exploratory Factor Analysis
In this project, we combine extensive data simulations and supervised machine learning to create new factor retention criteria that can accurately predict the dimensionality of a latent concept given various data characteristics. In simulation studies, these machine-learning-based approaches show a consistently higher accuracy than common factor retention criteria as well as higher replicability rates for empirical data sets.
Selected Publications and Preprints:
Goretzko, D., & Bühner, M. (2020). One model to rule them all? Using machine learning algorithms to determine the number of factors in exploratory factor analysis. Psychological Methods, 25(6), 776–786. https://doi.org/10.1037/met0000262
Goretzko, D., & Bühner, M. (2022). Factor retention using machine learning with ordinal data. Applied Psychological Measurement, 46(5), 406-421. https://doi.org/10.1177/01466216221089345
Goretzko, D., & Ruscio, J. (2024). The Comparison Data Forest – A new comparison data approach to determine the number of factors in exploratory factor analysis. Behavior Research Methods. https://doi.org/10.3758/s13428-023-02122-4
Goretzko, D. (2025). How many factors to retain in exploratory factor analysis? A critical overview of factor retention methods. Psychological Methods. https://doi.org/10.1037/met0000733
Goretzko, D., Partsch, M. V., & Sterner, P. (2025). Embrace the heterogeneity in EFA but be transparent about what you do – A commentary on Manapat et al. (2023). Psychological Methods. https://doi.org/10.1037/met0000759